
Una de las tareas del proyecto ICTUSnet es el desarrollo de herramientas de minería de textos (TM) para asistir en el proceso de extracción de información relevante para la evaluación de la calidad asistencial. La información se extrae de los informes de alta hospitalaria de pacientes diagnosticados con ictus y se compila en un registro centralizado. La unidad de Text Mining del Barcelona Supercomputing Center lidera el desarrollo de estas herramientas dentro del proyecto.
Para esta tarea disponíamos de 2696 informes de alta de AQuAS y 611 informes del Hospital Universitario Son Espases (HUSE) y lo primero que hicimos fue seleccionar el subconjunto de informes a anotar para, después, poder entrenar y evaluar los algoritmos de TM.
HUSE da cobertura a la población de las Islas Baleares mientras que los datos de AQuAS proceden de los 26 hospitales que dan cobertura a la población de Cataluña. Así que decidimos usar la proporción de la población a la que da cobertura cada una de las fuentes, con lo que el 13% de los informes que forman el corpus se seleccionaron del HUSE y el 87% de AQuAS .
Para los datos de AQuAS, quisimos mantener también la heterogeneidad (proceden de 26 hospitales distintos), y para ello separamos los documentos en clusters (ver detalles del clustering al final). Este ejercicio nos ha permitido tener una visión de la heterogeneidad de los informes. En el gráfico siguiente podemos ver todos los informes proyectados en el plano donde los colores representan los diferentes cluster (8 en total).
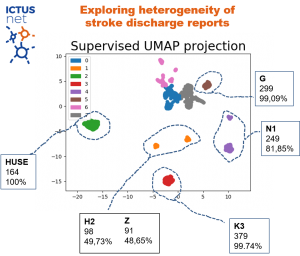
Al mirar con detalle los datos, observamos que los clusters se corresponden de manera bastante fiel a la procedencia de los informes. Así, el cluster verde (2) está constituido exclusivamente por los 164 informes del HUSE, mientras que el cluster rojo (3) contiene 379 informes del hospital K3 que representan el 99.74% del cluster. A su vez, el cluster lila (4) contiene 249 informes del hospital N1 representando el 81,85% del cluster. El cluster naranja (1) está repartido (casi mitad y mitad) por documentos de los hospitales H2 y Z.
El grupo formado por los clusters 0,6 y 7 recoge informes de hasta 24 hospitales diferentes, 19 de los cuales en un porcentaje superior al 90% (es decir, más del 90% de los informes del hospital pertenecen a este grupo).
Observamos una tendencia evidente a la concentración de los informes de un determinado hospital en un único cluster. Así, de media, el 89,6% de los informes de un hospital se concentran en un mismo cluster, siendo la concentración mayor la del 100% y la menor la del 52% (72% si agrupamos los clusters 0, 6 y 7 en un único grupo).
Para realizar el clustering hemos seguidos los siguientes pasos:
- Utilizacion la implementación de Gensim de doc2vec con los embeddings médicos en Soares, Felipe, et al. “Medical word embeddings for Spanish: Development and evaluation.” Proceedings of the 2nd Clinical Natural Language Processing Workshop. 2019.
- Una vez generados los vectores de cada documento, utilizamos UMAP supervisado para reducir la dimensionalidad, indicando las dos fuentes de datos como el label de cada ID, y usando la distancia de coseno. Establecemos random_state = 0 y el resto de parámetros por defecto.
- Sobre este output aplicamos K-means con k=8 y random_state = 0. Todos los documentos de HUSE caen en el mismo cluster, y ninguno de AQuAS cae en este cluster.